在最近的编程练习和写东西的过程中,常常用到了fopen和fread两个函数来读取本地文件。之前使用这两个函数时,一直没有出现过什么问题。也是因为没有出现问题,对这两个函数的用法的一些细节没有很了解,所以导致这次使用出现了问题。
这次在尝试写一个简单C编译器的过程中,第一步就是需要从本地读取需要编译的源码文件,于是自然又想到了这两个函数。但是在使用过程中,出现了一些奇怪的问题。具体问题就是:将本地文件读取到内存中,在控制台输出读到的文件内容,结果发现控制台输出中读到的数据不对,末尾数据多了部分字符。
程序源码如下:
1 #include2 #include 3 #include 4 #include 5 #define MAX_SIZE 256*1024 6 7 char src[MAX_SIZE]; 8 9 int main(int argc ,char** argv)10 {11 char file_name[256];12 printf("input file name:");13 scanf("%s",file_name);14 int line=1;15 FILE * fp=NULL;16 int i=0;17 if((fp=fopen(file_name,"r"))<0)18 {19 printf("open file fail!\n");20 return -1;21 }22 memset(src,0,sizeof(MAX_SIZE));23 if ((i=fread(src,1,MAX_SIZE-1,fp))&&i<0)24 {25 printf("read return %d\n",i);26 }27 printf("%s",src);28 system("pause");29 return 0;30 }
需要读取的文件是test.cpp(放在工程源码目录下),文件中的内容如下:
1 #include2 using namespace std;3 4 int main()5 {6 cout<<"hello world"<
在VS或者Dev中编译运行源码,结果如下图所示:
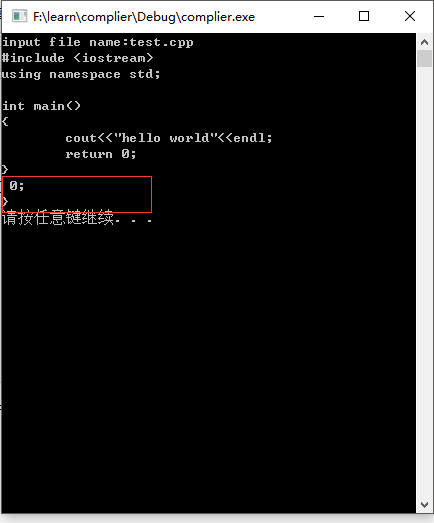
其中画红框部分即为多读的数据。为什么会出现这样的问题?
源码的逻辑过程很简单没有什么错误,那就是在函数的使用上有问题。这里与文件读取有关的就是fopen和fread这两个函数。先来看看fopen函数的原型及参数:
FILE * fopen(const char * path,const char * mode);
第一个参数显然是需要打开的文件路径。第二个参数是文件打开的方式,具体就是控制打开的文件的读取权限和文本方式打开还是二进制文件打开。而该函数的返回值是一个FILE结构体指针。
关于上面产生的错误,其实就是由于文件打开方式不适造成的,这个可能也是很多人容易忽略的。因为觉得只要调用了fopen函数并且加个if判断文件打开成功就没问题了。但是其实第二个参数也会带来问题。回头看看源码中fopen的调用方法,发现第二个参数是"r",即以只读方式打开文件(更多参数自行百度),但是并没有指明是以文本方式打开还是以二进制方式打开。其实,当没有显示声明文件打开方式的时候,该函数默认使用文本方式打开文件,即参数"r"其实等同于"rt"(r:read的缩写、t:txt的缩写)。也正是因为这个原因,造成了上面的错误。在这里,只要把fopen的第二个参数改成"rb",即以二进制文件打开文件,就不会出现上面的错误了。而以文本方式打开文件,可能是因为做了一些字符替换,于是导致了上述的错误。
在这里,可以去了解一下什么是文本文件,什么是二进制文件。文件以文本方式打开和以二进制方式打开有什么区别?
再来看看fread函数。fread从一个文件流中读数据,最多读取count个元素,每个元素size字节,如果调用成功返回实际读取到的元素个数,如果不成功或读到文件末尾返回 0。其函数原型及参数如下:
size_t fread ( void *buffer, size_t size, size_t count, FILE *stream) ;
buffer:接收数据的内存地址
size:每个数据项的字节数,单位是字节。
count:要读取count个数据项,每个数据项size个字节。
stream:输入流
返回值是size_t类型,这也是一个值得留意的地方。
看完上面的参数,来稍微解释一下fread是怎么进行的。fread最多读取size*count个字节,但是不是一次读取完,而是每次读取size个字节,一共读count次。当某次读取不足size字节时,则读到了文件末尾,并返回一共成功读了几次size字节。下面举个例子说明:假设fp指向一个5个字节的文件,调用fread函数将文件内容读到buffer:
int i=fread(buffer,2,10,fp);
上面的调用表示最多读取10次,每次读取2个字节,而文件只有5个字节,那么i的值是多少?答案是2.第一次读取两个字节,第二次再读取两个字节,到了第三次,只剩下一个字节了,不足一个size的大小,所以这次不进行计数,因此返回值是2,而不是3.
同样的,fread对应的函数fwrite有着类似的参数和执行过程。